
Google DeepMind ha annunciato un modello di intelligenza artificiale chiamato V2A (video-to-audio) che può generare audio sincronizzato, compresi musica, effetti sonori e dialoghi, per input video. Questa tecnologia si propone di migliorare la realtà virtuale dei video generati da AI mediante la creazione di soundtrack appropriati direttamente dai pixel del video, senza bisogno di allineamento manuale o descrizioni di testo.
- Si distingue dalle soluzioni esistenti grazie alla capacità di comprendere i pixel del video senza richiedere allineamento manuale del suono con le immagini
- Utilizza il toolkit SynthID di DeepMind per marchiare il contenuto generato da AI, aiutando a proteggere contro il possibile abuso
V2A utilizza un approccio basato sulla diffusione per generare audio realistico. Il sistema codifica l’input video in una rappresentazione compressa, che guida il modello di diffusione a raffinare iterativamente l’audio partendo dal rumore casuale. Questo processo è condizionato dall’input visivo e da testi opzionali, generando audio sincronizzato che si adatta strettamente alle azioni sullo schermo. L’audio generato viene quindi decodificato in un’onda sonora e combinato con i dati del video.
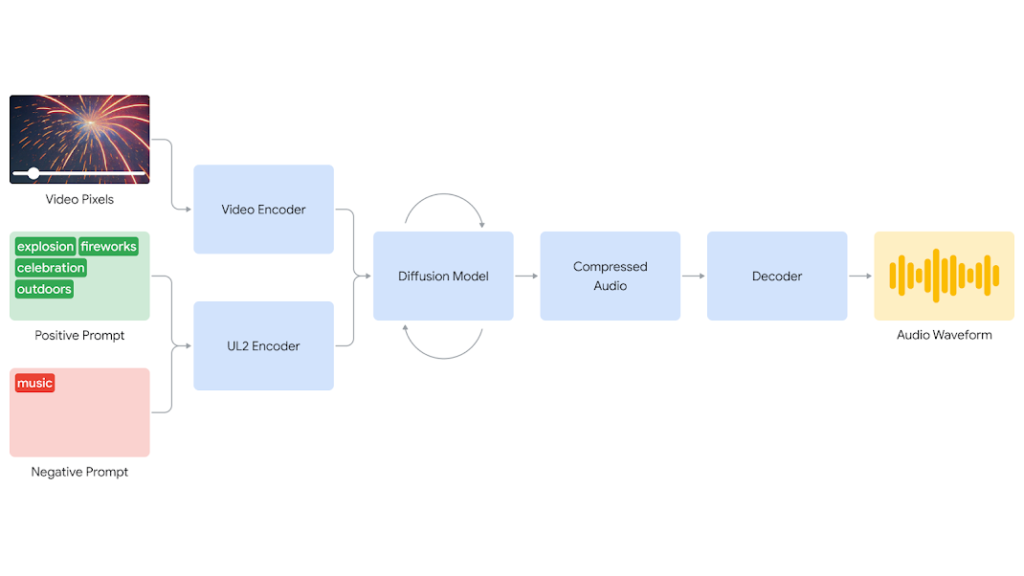
Per migliorare la qualità dell’audio e permettere la generazione di suoni specifici, DeepMind ha addestrato il modello su dati aggiuntivi come annotazioni di suoni generati da AI e trascrizioni di dialoghi. Ciò consente a V2A di associare gli eventi audio ai scene visive e di rispondere alle annotazioni o trascrizioni fornite.
- Consente di sperimentare rapidamente con diversi output audio per un video dato, generando un numero illimitato di soundtrack
- Potenziale per rivoluzionare i flussi di produzione video e aprire nuove opportunità creative
Tuttavia, V2A presenta ancora alcune limitazioni da affrontare. La qualità dell’audio dipende dalla qualità dell’input video, con artefatti o distorsioni che portano a cali notevoli nella fidelità audio. La sincronizzazione delle labbra per i video di conversazione richiede miglioramenti, poiché il modello di generazione di video non può sempre sincronizzare correttamente le movimenti delle labbra con il testo.
DeepMind si concentra su questi sfide e raccoglie feedback dai creatori e dai filmmaker per assicurare un impatto positivo sulla comunità creativa. Gli esami rigorosi e le prove sono pianificate prima di considerare la pubblicazione, con risultati iniziali che mostrano promesse per portare i film generati da AI alla vita. La società si impegna a sviluppare AI in modo responsabile, incorporando marchi di SynthID per identificare il contenuto generato da AI e proteggere contro l’abuso.
https://deepmind.google/discover/blog/generating-audio-for-video
Lascia un commento
Devi essere connesso per inviare un commento.