
Generare Dati Sintetici con Nemotron-4 340B di NVIDIA
NVIDIA ha recentemente annunciato il rilascio di Nemotron-4 340B, una famiglia rivoluzionaria di modelli progettati per generare dati sintetici per l’addestramento di modelli di linguaggio su larga scala (LLM) in vari ambiti commerciali. Questo lancio rappresenta un importante passo avanti nell’intelligenza artificiale generativa, offrendo un insieme completo di strumenti ottimizzati per NVIDIA NeMo e NVIDIA TensorRT-LLM, inclusi modelli all’avanguardia per istruzioni e ricompense.
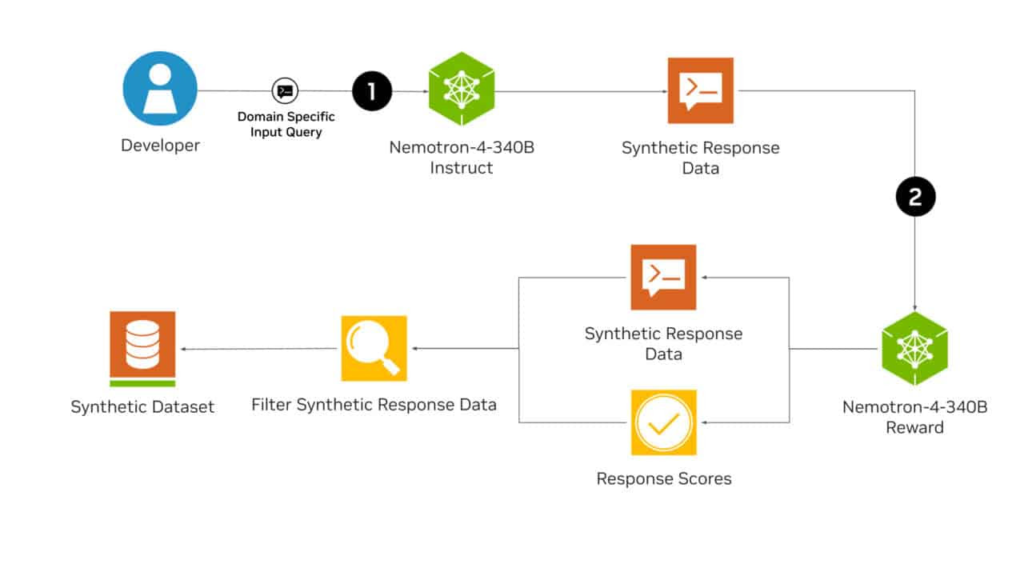
Questa iniziativa mira a fornire agli sviluppatori un mezzo conveniente e scalabile per accedere a dati di addestramento di alta qualità, elemento cruciale per migliorare le prestazioni e l’accuratezza di LLM personalizzati. La famiglia Nemotron-4 340B include tre varianti: modelli per Istruzioni, Ricompense e Base, ognuno con funzioni specifiche nel processo di generazione e raffinamento dei dati.
Modello Nemotron-4 340B per Istruzioni
Il modello Nemotron-4 340B per Istruzioni è progettato per creare dati sintetici diversificati che imitano le caratteristiche dei dati del mondo reale, migliorando le prestazioni e la robustezza di LLM personalizzati in vari domini. Questo modello è essenziale per generare i dati di output iniziali, che possono essere ulteriormente raffinati e migliorati.
Modello Nemotron-4 340B per Ricompense
Il modello Nemotron-4 340B per Ricompense svolge un ruolo cruciale nel filtrare e migliorare la qualità dei dati generati dall’IA. Esso valuta le risposte in base a utilità, correttezza, coerenza, complessità e verbosità. Questo modello garantisce che i dati sintetici siano di alta qualità e rilevanti per le esigenze dell’applicazione.
Modello Nemotron-4 340B Base
Il modello Nemotron-4 340B Base funge da struttura di base per la personalizzazione. Addestrato su 9 trilioni di token, questo modello può essere perfezionato utilizzando dati proprietari e vari dataset per adattarsi a casi d’uso specifici. Supporta un’ampia personalizzazione attraverso il framework NeMo, consentendo il perfezionamento supervisionato e metodi efficienti dal punto di vista dei parametri come low-rank adaptation (LoRA).
Questa innovativa famiglia di modelli vanta specifiche impressionanti, tra cui una finestra di contesto di 4k, l’addestramento in oltre 50 e 40 lingue di programmazione, e il raggiungimento di benchmark notevoli come 81,1 MMLU, 90,53 HellaSwag e 85,44 BHH. I modelli richiedono una potenza di calcolo significativa, inclusi 16 GPU H100 in bf16 e circa 8 H100 in configurazioni int4.
I dati di addestramento di alta qualità sono importanti per sviluppare LLM robusti, ma spesso comportano costi e problemi di accessibilità sostanziali. Nemotron-4 340B affronta questa sfida consentendo la generazione di dati sintetici attraverso una licenza open model permissiva. Questa famiglia di modelli include modelli base, per istruzioni e per ricompense, formando una pipeline che facilita la creazione e il raffinamento di dati sintetici. Questi modelli sono perfettamente integrati con NVIDIA NeMo, un framework open-source che supporta l’addestramento end-to-end dei modelli, comprendendo la preparazione dei dati, la personalizzazione e la valutazione. Sono inoltre ottimizzati per l’inferenza utilizzando la libreria NVIDIA TensorRT-LLM, migliorandone l’efficienza e la scalabilità.
Il modello Nemotron-4 340B per Istruzioni è particolarmente degno di nota in quanto genera dati sintetici che imitano da vicino i dati del mondo reale, migliorando la qualità dei dati e aumentando le prestazioni di LLM personalizzati in diversi ambiti. Questo modello può creare output di dati vari e realistici, che possono essere ulteriormente raffinati utilizzando il modello Nemotron-4 340B per Ricompense. Il modello per Ricompense valuta le risposte in base a utilità, correttezza, coerenza, complessità e verbosità, garantendo che i dati generati soddisfino standard di alta qualità. Questo processo di valutazione è fondamentale per mantenere la rilevanza e l’accuratezza dei dati sintetici, rendendoli adatti a varie applicazioni.
Un vantaggio chiave di Nemotron-4 340B è la sua capacità di personalizzazione. Ricercatori e sviluppatori possono adattare il modello di base utilizzando dati proprietari, incluso il dataset HelpSteer2, consentendo la creazione di modelli personalizzati per istruzioni o ricompense. Questo processo di personalizzazione è essenziale per soddisfare le esigenze specifiche di ogni caso d’uso.
In conclusione, Nemotron-4 340B di NVIDIA rappresenta un importante passo avanti nella generazione di dati sintetici per l’addestramento di LLM. La sua licenza open model permissiva offre agli sviluppatori un mezzo gratuito e scalabile per accedere a dati di addestramento di alta qualità, essenziali per migliorare le prestazioni e l’accuratezza dei LLM personalizzati in una vasta gamma di applicazioni commerciali.
Download Nemotron-4 340B models via Hugging Face. For more details, read the research papers on the model and dataset.
Lascia un commento
Devi essere connesso per inviare un commento.