
Un recente studio da HAI Stanford Universityha rivelato che i grandi modelli linguistici utilizzati ampiamente per le valutazioni mediche non riescono a supportare adeguatamente le loro affermazioni.
L’uso dei modelli linguistici di grandi dimensioni (LLM) nel campo medico sta diventando sempre più diffuso. Un numero significativo di medici, fino a uno su dieci, ha già integrato l’utilizzo di modelli come ChatGPT nella propria pratica quotidiana, mentre i pazienti stanno sempre più spesso utilizzando ChatGPT per effettuare auto-diagnosi. Tuttavia, questa rapida adozione avviene nonostante le notevoli incertezze riguardo alla sicurezza, all’efficacia e al rischio associato all’utilizzo dell’intelligenza artificiale generativa (GenAI) nel contesto medico.
La GenAI si trova in una sorta di “zona grigia” tra due forme di tecnologia esistenti nel settore sanitario. Da un lato, ci sono siti come WebMD che forniscono informazioni mediche rigorosamente basate su fonti credibili, non soggetti a regolamentazione da parte della FDA.
Dall’altro lato, ci sono dispositivi medici che interpretano le informazioni dei pazienti e formulano previsioni, che sono soggetti a una stretta valutazione da parte della FDA.
Il problema principale è che i LLM producono una combinazione di informazioni mediche esistenti e idee potenziali, sollevando dubbi sulla loro capacità di fornire riferimenti accurati per supportare le loro risposte. Questi riferimenti sono fondamentali per permettere ai medici e ai pazienti di verificare le valutazioni della GenAI e proteggersi da possibili errori.
Un esempio emblematico è quello di Alex, un bambino di 4 anni la cui malattia cronica è stata diagnosticata da ChatGPT dopo che più di una dozzina di medici non erano riusciti a farlo. Tuttavia, mentre un LLM può produrre una diagnosi corretta come nel caso di Alex, ci sono molti altri pazienti che potrebbero essere indotti in errore dalle “allucinazioni” generate dai modelli.
Una valutazione dettagliata della capacità dei LLM di supportare le rivendicazioni è stata condotta utilizzando un nuovo approccio di valutazione.
I risultati hanno dimostrato che la maggior parte dei modelli non è in grado di produrre riferimenti adeguati per supportare le risposte. Anche il modello più avanzato, GPT-4 con generazione potenziata dal recupero, mostra una percentuale significativa di affermazioni non supportate e risposte incomplete.
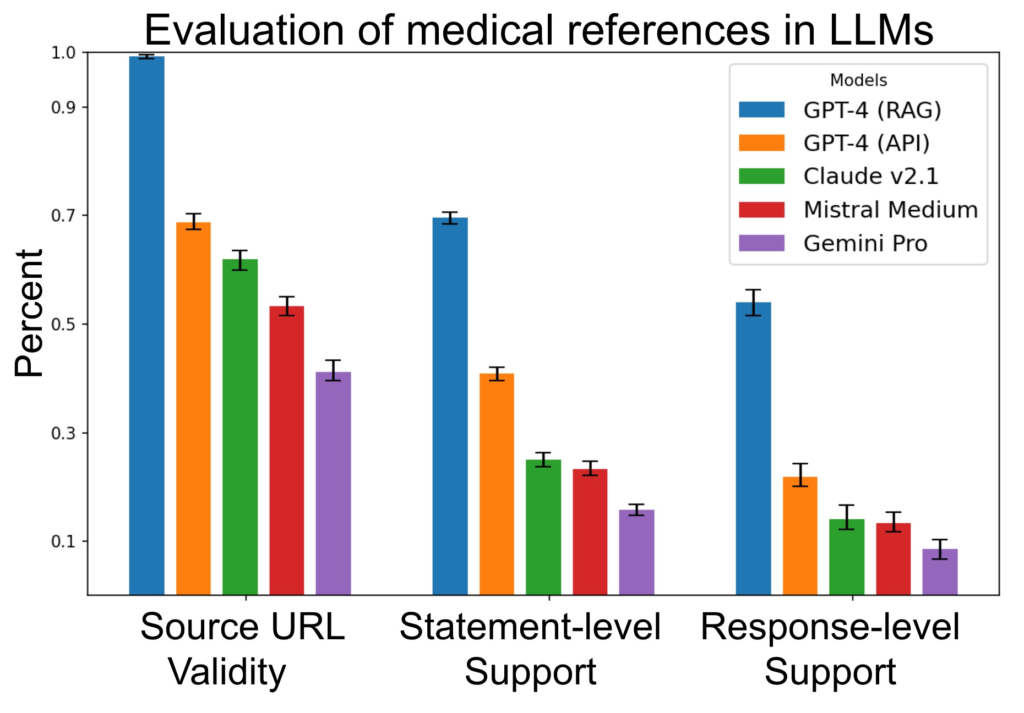
Per affrontare questo problema, è necessario sviluppare nuovi approcci e flussi di lavoro di valutazione, come il SourceCheckup, che permettono di verificare la validità delle risposte prodotte dai LLM. Inoltre, è fondamentale sottolineare che gli errori sono più frequenti nelle richieste provenienti da non esperti, suggerendo che i LLM potrebbero non essere in grado di fornire informazioni affidabili a coloro che ne hanno più bisogno.
Nonostante le promesse della GenAI nel campo medico, ci sono ancora molte sfide da affrontare. È essenziale condurre ulteriori ricerche e sviluppare approcci più sofisticati per valutare e integrare i modelli linguistici di grandi dimensioni nella pratica medica.
Lascia un commento
Devi essere connesso per inviare un commento.