
Oggi è stato integrato su più piattaforme e rilasciato in più mercati globali l’assistente di intelligenza artificiale di Meta Platforms , Meta AI, basato su Meta Llama 3.
Hanno utilizzato molti più dati e Zuckerberg vuole mettere il modello all’interno di Whatsapp, Instagram e Facebook, siete pronti?
Meta AI, rivale di ChatGPT di OpenAI, può ora essere utilizzato su tutte le app di Meta, tra cui Facebook, Instagram, WhatsApp e Messenger.
È possibile accedervi anche da un sito Web autonomo: Meta AI .
Questa versione spiega l’azienda presenta modelli linguistici pre-addestrati e ottimizzati per seguire istruzioni con 8B e 70B parametri, in grado di supportare un’ampia gamma di applicazioni d’uso.
⏺ Training Data: Trained on a massive 15 trillion token dataset (7x larger than Llama 2). Over 5% of data consists of non-English text covering 30+ languages
⏺ Broad Platform Support: Available on @AWS, @Databricks, @Google Cloud platforms and more.
⏺ Advanced AI Capabilities: Includes improved reasoning, longer context windows, and better overall AI performance
⏺ Safety and Responsibility Features: Features tools like Llama Guard 2 and Code Shield to ensure safe use.
⏺ Industry-Leading Performance: Sets new benchmarks in performance compared to previous models.
⏺ Future Enhancements Planned: Upcoming models with up to 400B parameters and new capabilities like multimodality.
⏺ Meta AI Integration: Powers Meta’s AI assistant for enhanced user experiences across various platforms.
✅ It’s Open Source! https://www.meta.ai/
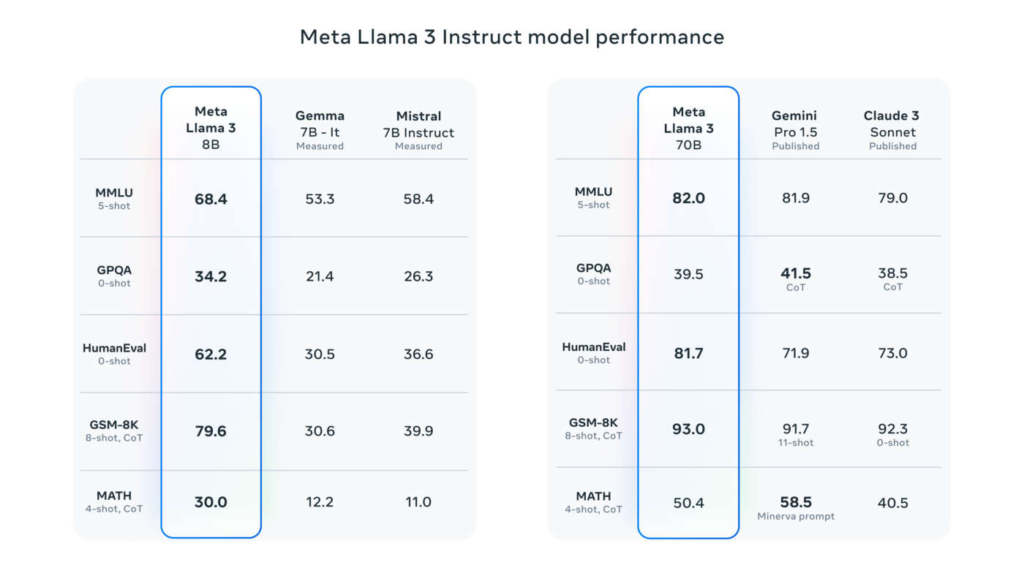
Questa nuova generazione di Llama secondo Meta dimostra prestazioni superiori su un’ampia gamma di benchmark standard di settore e offre nuove funzionalità, tra cui un ragionamento migliorato. L’azienda ritiene che questi siano i migliori modelli open source della loro categoria.
Meta AI in inglese viene rilasciato anche in più di una dozzina di paesi al di fuori degli Stati Uniti, tra cui Australia, Canada, Ghana, Giamaica, Malawi, Nuova Zelanda, Nigeria, Pakistan, Singapore, Sud Africa, Uganda, Zambia e Zimbabwe.
L’aggiornamento a Meta AI ha anche migliorato le sue capacità di generazione di immagini.
“Stiamo velocizzando la generazione di immagini, in modo da poter creare immagini dal testo in tempo reale utilizzando la funzione Imagine di Meta AI”,
ha affermato Meta in un comunicato stampa.
“Stiamo iniziando a implementarlo oggi in versione beta su WhatsApp e sull’esperienza web Meta AI negli Stati Uniti.”
I modelli Llama 3 saranno presto disponibili su AWS , Databricks, Google Cloud, Hugging Face, Kaggle, IBM WatsonX, Microsoft Azure, NVIDIA NIM e Snowflake e con il supporto di piattaforme hardware offerto da AMD , AWS, Dell , Intel , NVIDIA e Qualcomm , ha affermato Meta .
AWS ha inoltre affermato che Meta Llama 3 è disponibile su Amazon SageMaker JumpStart.
“Llama 3 utilizza un’architettura trasformatore esclusivamente decoder e un nuovo tokenizzatore che fornisce prestazioni migliorate del modello con dimensioni di 128k”, ha affermato la portavoce di AWS Emma Quong.
“Inoltre, Meta ha migliorato le procedure post-formazione che hanno sostanzialmente ridotto i tassi di falsi rifiuti, migliorato l’allineamento e aumentato la diversità nelle risposte dei modelli.”
“Nei prossimi mesi, prevediamo di introdurre nuove funzionalità, finestre di contesto più lunghe, dimensioni di modelli aggiuntivi e prestazioni migliorate, e condivideremo il documento di ricerca di Llama 3”,
ha aggiunto Meta.
Meta ha lanciato il suo modello linguistico di grandi dimensioni Llama 2 nel luglio 2023.
Alcune delle sue misure di sicurezza erano considerate “troppo sicure” in quanto voleva evitare alcune delle insidie incontrate da Geminidi Google.
Questa nuova versione include nuovi strumenti di protezione e sicurezza con Llama Guard 2, Code Shield e CyberSec Eval 2.
24 Aprile aggiornamento
Modelli linguistici di grandi dimensioni migliori e più veloci tramite previsione multi-token
I modelli linguistici di grandi dimensioni come GPT e Llama vengono addestrati con una perdita di previsione del token successivo. In questo lavoro, suggeriamo che l’addestramento di modelli linguistici per prevedere più token futuri contemporaneamente si traduca in una maggiore efficienza del campione. Più specificamente, in ciascuna posizione nel corpus di addestramento, chiediamo al modello di prevedere i seguenti n token utilizzando n teste di output indipendenti, operando su un tronco del modello condiviso. Considerando la previsione multi-token come un’attività di formazione ausiliaria, misuriamo le capacità a valle migliorate senza costi aggiuntivi in termini di tempo di formazione sia per i modelli di codice che per quelli in linguaggio naturale. Il metodo è sempre più utile per modelli di dimensioni maggiori e mantiene il suo fascino durante l’addestramento per più epoche. I guadagni sono particolarmente pronunciati sui benchmark generativi come la codifica, dove i nostri modelli superano costantemente le solide linee di base di diversi punti percentuali. I nostri modelli con parametri 13B risolvono il 12% in più di problemi su HumanEval e il 17% in più su MBPP rispetto a modelli next-token comparabili. Esperimenti su piccoli compiti algoritmici dimostrano che la previsione multi-token è favorevole allo sviluppo di teste di induzione e capacità di ragionamento algoritmico. Come ulteriore vantaggio, i modelli addestrati con la previsione a 4 token sono fino a 3 volte più veloci nell’inferenza, anche con batch di grandi dimensioni.
Newsletter AI – non perderti le ultime novità sul mondo dell’Intelligenza Artificiale, i consigli sui tool da provare, i prompt e i corsi di formazione. Iscriviti alla newsletter settimanale e accedi a un mondo di contenuti esclusivi direttamente nella tua casella di posta!
Lascia un commento
Devi essere connesso per inviare un commento.