
Questa settimana, noi di Redazione Rivista.AI siamo andati a un paio di convegni e la parola Hype e’ stata sparsa come lo zucchero a velo sul pandoro o spread thin like butter on toast come dicono gli anglofoni.
Ci e’ sembrato doveroso scrivere una articolo nella sezione Vision, di venerdi sera, sperando che abbiate abbastanza tempo durante il Weekend per leggerlo. Altrimenti fermatevi all’elevetor pitch :
I grandi modelli linguistici (LLM) e l’intelligenza artificiale generativa (GenAI) stanno attualmente rivoluzionando numerosi settori e stanno trasformando radicalmente la nostra vita quotidiana.
Finora, l’approccio principale per monetizzare la GenAI è stato orientato verso i flussi di entrate Business-to-Business (B2B), ma si sta iniziando a osservare un crescente interesse verso l’implementazione di modelli basati su abbonamento e l’introduzione del “GPT Store”, che mostra promesse anche per gli utenti individuali.
Allo stesso tempo, la progettazione di hardware e software, unita agli strumenti per ottimizzare i flussi di lavoro dell’intelligenza artificiale e le opportunità nell’applicazione pratica dell’intelligenza artificiale, emergono come aree chiave da monitorare attentamente nello spazio della GenAI.
Una delle storie principali, se non la storia del 2023 per il mondo degli investimenti, del giornalismo e delle accademie è stata l’avvento dei modelli linguistici di grandi dimensioni (“LLM”), il loro utilizzo come motore dell’intelligenza artificiale generativa (GenAI) e come, lentamente ma inesorabilmente, la GenAI ha iniziato a riscrivere la vita come la conosciamo.
Comprensibilmente, in un periodo di grande incertezza che un simile sconvolgimento porta con sé, diventa estremamente difficile separare il lampo dalla sostanza (De rerum natura).
Abbiamo trascorso una parte significativa dell’anno analizzando varie offerte di GenAI e, mentre riflettiamo, volevamo condividere la nostra valutazione dello stato di GenAI, sollevare un po’ il sipario su quanto sia realmente vicino al messia che definisce l’era di sogno o incubo e preparare il terreno per il prossimo anno dal punto di vista aziendale per i principali attori in questo spazio.
La frase magica che abbiamo in mente negli ultimi mesi riguardo alla capacità di trasformazione dell’IA è moltiplicatore di forza .
Certo, sa di linguaggio aziendale, ma dal punto di vista dei principi primi descrive in modo abbastanza accurato ciò che l’intelligenza artificiale generativa ha reso disponibile alle masse.
Se si perdona di portare all’estremo l’analogia meccanica, è simile a ciò che la stampa ha fatto per la proliferazione della parola scritta.
La chiave di queste due scoperte, tuttavia, è l’ effetto moltiplicatore , ovvero il modo in cui il lavoro (continuo) di pochi fornisce benefici a un numero maggiore di individui. Tutti i LLM di oggi possono far risalire le loro radici al documento fondamentale sul modello del trasformatore, ” L’attenzione è tutto ciò di cui hai bisogno “, (Attention Is All You Need) con solo otto autori elencati.
Fare molto con poco è una tesi piuttosto ampia, lo ammettiamo, soprattutto con gran parte della tecnologia fondamentale ancora in evoluzione.
La grande domanda che ci poniamo ogni volta che esce qualche notizia di origine aziendale che parla di intelligenza artificiale è: qual è la storia della monetizzazione? (deformazione professionale avendo speso la maggior parte della vita in US corporations)
È stata data così tanta enfasi alla creazione di modelli più grandi e migliori a tutti i costi, riecheggiando stranamente il modello di startup di iper-crescita dell’ultimo decennio: prima gli utenti, poi i ricavi.
Con i progressi LLM sottostanti che si avvicinano rapidamente allo stato stazionario, convertire gli utenti in entrate è ora più importante che mai per compensare gli ingenti costi infrastrutturali necessari per addestrare e ospitare tali modelli.
Da dove siamo, gran parte della monetizzazione iniziale si è concentrata su flussi di entrate di tipo B2B (o, più precisamente, “dev-to-dev”).
Ogni giocatore di intelligenza artificiale è fin troppo ansioso di distribuire chiavi API come caramelle, ma le chiavi API non sono il tipo di cosa a cui un individuo medio è troppo interessato, insieme a cose come il “prezzo per token” con cui viene fatturato l’accesso all’API. , quindi la maggior parte delle persone sperimenterà la “magia” dell’IA solo attraverso altre modalità: chatbot, copilota, implementazione di funzionalità dietro le quinte, ecc.
Alcune di queste indicazioni indirette derivano anche dalla necessità di fornire basi approfondite per prevenire allucinazioni e tossicità , “spontaneo” o provocato da un cattivo attore.
Pertanto, in questa fase, gli altri sviluppatori sembrano gli individui più sicuri a cui gli autori del modello possono affidare l’accesso diretto al modello (oltre a rendere più semplice il controllo dell’accesso controllando gli input e revocando le chiavi per i cattivi attori comprovati).
Detto questo, OpenAI ha mostrato qualche promessa per i modelli di entrate “AI-as-a-service” basati su abbonamento, dato il feedback positivo che le persone che utilizzano ChatGPT Plus, basato su GPT-4, hanno fornito sull’esperienza.
Non siamo convinti che questo tipo di modalità “chatbot premium” sia una fonte di entrate che può crescere esclusivamente rivolgendosi direttamente ai privati; dopo un po’ inizierai a vedere la “condivisione della password” prendere piede e la crescita ristagnerà.
C’è un nuovo sviluppo, sempre di OpenAI, che riteniamo abbia il potenziale per spingere ulteriormente la monetizzazione: il “GPT Store“.
I paralleli con l’introduzione dello smartphone e dell'”App Store” sono calzanti, non aggiustano ciò che non è rotto quando si tratta di fidarsi della saggezza (e della creatività) delle masse. Daltronde forse sara’ quello a cui saranno interessate a questecome il sig. Jobs ci ha insegnato.
Democratizzare il processo di perfezionamento, lasciare che le persone votino con il loro tempo e i loro portafogli, raccolgano il feedback e ripetano l’intero ciclo.
Hardware: i dadi e i bulloni e i cacciaviti
Per quanto magico possa sembrare, l’essenza di un LLM è il codice che esegue grandi quantità di operazioni matematiche su silicio specializzato e REE , il ciclo infinito della moderna ingegneria informatica. Il codice e il silicio sono in una sorta di fase “coevolutiva“, in cui ciascuno cerca di sfruttare la forza dell’altro pur rimanendo abbastanza flessibile da accogliere qualcosa di meglio in futuro.
Gli hyperscaler e gli sviluppatori di modelli si affidano alle GPU come spina dorsale dell’acceleratore preferito, probabilmente a causa della capacità di produttori come Nvidia Corporation di stipare enormi quantità di VRAM sulle schede, riducendo al minimo la necessità di dividere i carichi di lavoro su più acceleratori; e offrire un’esperienza di sviluppo integrata verticalmente con librerie come CUDA.
È un’esperienza quasi impossibile da replicare, il che spiega perché Nvidia ha una tale presa in questo ambito. Dato che Nvidia ha sostanzialmente creato e continua a guidare il settore delle GPU, non vediamo alcun motivo per cui non saranno in grado almeno di “crescere” e monopolizzare.
Nel frattempo, mentre i veri progettisti di chip (Applied Materials, ASM International e Lam Research ) ricevono la maggior parte dell’attenzione, non possono davvero lavorare senza l’aiuto delle attrezzature di fabbricazione ( fabrication equipment) gate-all-around or GAA, transistors and backside power delivery chip architectures, chiamate alla fine di novembre i proverbiali “picconi e pale” della corsa all’oro dell’IA.
Questa parte dello stack è il migliore. Noioso ma sforna denaro. In quanto investitori di valore, i produttori di apparecchiature hanno tutte le caratteristiche che il mercato ama : P/E basso, rendimento elevato del capitale proprio e debito netto minimo o nullo.
Cloud: la spina dorsale dell’AI.
L’enorme appetito dell’intelligenza artificiale per la potenza di calcolo è stato perversamente un vantaggio per i grandi fornitori di cloud, dando loro sia la possibilità di vendere unità di accelerazione AI agli utenti finali, sia di confezionare i propri LLM in API e addebitare tramite token per l’integrazione in soluzioni più grandi.
Laddove in precedenza tutti i costi infrastrutturali per l’intelligenza artificiale all’interno del cloud erano enormi miniere di denaro per gli hyperscaler, sostenuti dai LLM di Microsoft e Alphabet alias Google , ora hanno prodotto dopo prodotto supportato da soluzioni basate su LLM in esecuzione esclusivamente su il loro hardware cloud, aiutandoli a monetizzare effettivamente tutta quella spesa.
La ciliegina sulla torta > AI Workflow enhancers
Consentire agli utenti di eseguire la stessa quantità di lavoro con uno sforzo molto minore non è mai un cattivo investimento, tanto più se è possibile garantire un’offerta valida con un’elevata fedeltà al prodotto. Caso in questione: Slack, che ha il suo esercito di utenti devoti anche se la pura offerta di prodotti sembra non essere altro che un’app di chat threaded con supporto plug-in. Ecco alcune categorie generali relative allo sviluppo del modello:
- Librerie per descrivere una topologia del modello e un regime di training
- Repository per diverse parti del ciclo di vita dell’IA: set di dati, schede modello, diverse attività di formazione
- Approcci semplificati per la richiesta legale dei dati in modo da rispettare i desideri dei creatori di contenuti originali
- Archiviazione e hosting efficienti per set di dati e modelli addestrati.
Insieme agli hyperscaler, i fornitori di archiviazione dati come Couchbase, MongoDB e soprattutto Snowflake e Databricks sono probabilmente nella posizione migliore per aggiungere valore a questa parte dello stack.
Il fabbisogno di dati ML è già enorme e non mostra segni di diminuzione; avere visibilità e verificabilità di tali pile di dati sarà fondamentale per lavorare in questo spazio. Il loro destino potrebbe essere fortemente legato al decollo dell’intero settore dell’intelligenza artificiale. Anche l’ecosistema ML HuggingFace riempie molto bene quest’area con la sua suite di soluzioni standard per un’ampia gamma di attività; con modelli di grandi nomi come LLaMA e Phi-2 ospitati lì, non sarebbe una sorpresa vedere un grande nome della tecnologia finire per acquisirli.
Miglioramenti del toolkit AI
Partendo da modelli di base, la capacità di prenderli e migliorarne la formazione o integrarli in applicazioni più grandi è un altro ambito in cui il valore aggiunto rappresenterebbe un enorme vantaggio per gli sviluppatori, soprattutto se il passaggio dal prototipo alla produzione fosse il più agevole possibile. I compiti specifici su cui concentrarsi includono:
- Infrastruttura per la messa a punto degli LLM, in particolare una messa a punto efficiente dei parametri
- Integrazione efficiente con origini dati esterne, sia per flussi di lavoro “recupero aumentato” che per flussi di lavoro di orchestrazione
- Soluzioni integrate per garantire il rispetto delle linee guida etiche e sulla privacy, difendere gli utenti da risposte tossiche o attori IA indotti in modo dannoso, ecc.
Il GPT Store di OpenAI è l’esempio più chiaro di creazione di tali funzionalità il più vicino possibile al LLM stesso senza un’integrazione verticale completa. HuggingFace dispone di alcune soluzioni per la messa a punto e la libreria LangChain offre punti di integrazione unificati per LLM e altre varie origini dati.
Non abbiamo familiarità con nessun altro nome pubblico o che diventerà presto pubblico che faccia qualcosa in questo spazio, ma in questa fase del gioco è difficile offrire qualcosa che aggiunga più valore che limitarsi a vincolarsi a un particolare modello. ecosistema.
IA applicata , le candeline sulla torta
E in alto (o in basso, comunque tu scelga di vederla), abbiamo le opportunità di intelligenza artificiale applicata , che utilizza effettivamente un’intelligenza artificiale per fare qualcosa di vantaggioso che aggiunge valore rispetto alle alternative non basate sull’intelligenza artificiale.
È difficile dire che questo possa essere considerato un approccio commerciale in buona fede, data la massima “se tutti sono speciali, allora nessuno lo è”.
Forse potresti prendere in considerazione nuove opportunità di business come la “consulenza sull’intelligenza artificiale applicata“, assistenti virtuali specifici del dominio basati sull’intelligenza artificiale (abbiamo visto almeno due grandi aziende pubblicare annunci durante lo scorso fine settimana con un assistente basato sull’intelligenza artificiale) o che ci sia un’asimmetria in cui le industrie trarranno vantaggio dall’IA applicata e si rivolgeranno a quelle che avranno più da guadagnare dall’adozione dell’IA, i famosi verticali del portfoglio.
Dal punto di vista dell’utente finale, tuttavia, l’opportunità deriva dalla possibilità di “integrare” i miglioramenti dell’intelligenza artificiale in un’offerta di prodotti già radicata, in modo simile al punto “rendere le persone più efficienti” che abbiamo sottolineato in precedenza.
Caso in questione: Copilot for Office di Microsoft, che ha ricevuto grandi elogi dagli utenti e può sfruttare l’enorme base di utenti esistente di Microsoft per offrire un prezzo competitivo per postazione.
Nel moderno mondo SaaS basato su abbonamento, l’intelligenza artificiale ha davvero il potenziale per
a) generare nuove entrate,
b) preservare una base di abbonati esistente o addirittura
c) sottrarre abbonati riducendo drasticamente lo sforzo richiesto per eseguire attività con un determinato software applicazione (chi ha bisogno di Photoshop di Adobe ) quando puoi richiedere DALL-E o Midjourney?) ah.. dimenticavo ora c’e’ Adobe firefly.
Almeno un analista ha messo in evidenza la minaccia esistenziale dell’intelligenza artificiale al modello di business SaaS, con Adobe in pericolo più immediato.
Anche se la nostra visione è più moderata dal punto di vista del settore, crediamo che per i più grandi nomi SaaS sia giunto il momento di trovare modi per aggiungere valore per gli abbonati esistenti o aggiungere risparmi per lo stack tecnologico esistente con le attuali offerte di intelligenza artificiale, prima l’iterazione successiva o fa meglio il loro lavoro o rende un gioco da ragazzi produrre un prodotto concorrente.
Un altro ambito in cui si stanno scrivendo molte parole ma non riusciamo a trovare dati concreti a sostegno è l’effetto sulla “gig economy” personificata in piattaforme come Fiverr International.
Una rapida ricerca su Google rivela molti brevi post di blog (che sembrano generati dall’intelligenza artificiale) che esprimono opinioni su come la GenAI potrebbe trasformare il mercato dei concerti, analisti che ritengono che i venti contrari siano eccessivi, suggerimenti di persone su come diventare un lavoratore dei concerti che vende contenuti generati dall’intelligenza artificiale.
Anche storie di persone che si lamentano del fatto che le loro assunzioni su Fiverr forniscono solo contenuti generati dall’intelligenza artificiale quando si sono recati specificamente su Fiverr per trovare contenuti generati dagli esseri umani.
Come per le altre interruzioni in questo ambito, probabilmente vedremo i mercati e i servizi offerti coevolvere per garantire che i clienti ottengano il prodotto che desiderano e che i lavoratori siano in grado di trovare la loro clientela target indipendentemente dal loro kit di strumenti.
“Se c’è una possibilità che varie cose vadano male, quella che causa il danno maggiore sarà la prima a farlo“.
Ora che abbiamo esposto la tesi e l’abbiamo mostrata in azione (piu o meno), dovremmo evidenziare le aree più evidenti in cui l’hype ha il potenziale per dominare le onde radio rispetto agli attuali progressi tecnologici e alle nuove opportunità disponibili per i giocatori di intelligenza artificiale come un risultato.
Fallire: una via alternativa per avere successo
Sia che si cerchi di impressionare gli azionisti o i comitati di sovvenzione, di cui tutti abbiamo bisogno e che spesso rimangono celati dietro i nostri progetti R&D.. le storie più accattivanti sui nuovi modelli di intelligenza artificiale citano sempre qualche minimo miglioramento su un benchmark qui o su un set di dati là, ma è facile dimenticare due considerazioni importanti: il realismo e la praticità del modello dello scenario presentato.
Mentre ci tuffavamo nell’intelligenza artificiale con entrambi i piedi, abbiamo letto Designing Machine Learning Systems di Chip Huyen, il punto di vista di un ingegnere ben realizzato su come costruire e applicare sistemi ML per chi è esperto di computer ma non necessariamente la matematica profonda richiesta per i moderni sistemi di apprendimento automatico. M.L. Un passaggio emerge da una sezione sulla selezione del modello:
“I ricercatori spesso valutano i modelli solo in contesti accademici, il che significa che un modello all’avanguardia spesso significa che funziona meglio dei modelli esistenti su alcuni set di dati statici . Ciò non significa che questo modello sarà abbastanza veloce o abbastanza economico per da implementare. Ciò non significa nemmeno che questo modello funzionerà meglio di altri modelli sui tuoi dati.”
Sebbene questo consiglio sia stato in gran parte offerto nel contesto della costruzione di un modello autonomo e autonomo, la premessa si applica ancora alle soluzioni basate sull’intelligenza artificiale nel loro insieme. Come ha dimostrato l’annuncio di Google Gemini, questo tipo di presentazione può farsi strada nei lanci dei prodotti e nelle pubblicazioni.
Anche se gli hyperscaler come Google e Microsoft offrono di alleviare alcuni dei problemi di implementazione fornendo API, ciò non risolve ancora la questione se un LLM sia lo strumento giusto per il lavoro.
Il vecchio proverbio dice che

“Se l’unico strumento che hai in mano e’ un martello, ogni cosa iniziera’ a sembrarti un chiodo”
Non è cosi’ lontano potere affermare che molte presunte applicazioni basate sull’intelligenza artificiale che non finiranno per avere successo o, se lo fanno, saranno in realtà peggiori , dollaro per dollaro, euro su euro, di una non-AI o anche di una più semplice-ML- soluzione based.
che significa :
Per rendere un LLM utile per un’attività mirata o per un’interfaccia rivolta all’utente, è necessario dedicare molto impegno alla creazione di quello che viene chiamato “prompt di sistema”, una sezione di testo talvolta dettagliata, nascosta all’utente, che contiene un numero significativo di istruzioni e contesto intesi a mantenere l’output focalizzato e a proteggere l’utente da risposte errate.
Osservando un prompt di sistema da una delle demo di Gemini che mostra il ragionamento multimodale del modello, vediamo che il “codice” del linguaggio naturale utilizzato per produrre output per l’utente include:
- “Role setting”, una sorta di contesto in cui al modello viene detto di agire come esperto su un argomento per radicare le sue risposte
- Numerose chiamate a Gemini, in cui la modella ha elaborato testo e immagini caricate dall’utente
- Una descrizione dettagliata degli output che il modello dovrebbe generare in varie circostanze, solitamente in una sorta di formato di dati strutturati
- Ulteriori istruzioni contestuali riguardanti tono, verbosità, ecc.

Alla fine, l’effettivo input digitato dall’utente può costituire solo una piccola parte di ciò che viene inviato al modello.
La maggior parte delle interazioni basate sull’intelligenza artificiale che affermano di essere in grado di richiamare risorse esterne ed eseguire comportamenti “simili a quelli di un agente” sono in realtà sostenute da uno strato di codice “più semplice” che spinge l’LLM e utilizza le sue risposte per eseguire Azioni.
Facendo analogie con Who Wants to be a Millionaire, che ha avuto buoni risultati con esperti di dominio in Applied ML. Caso in questione: il seguente frammento di documentazione della funzione “Chiamata funzione” di OpenAI, che era parte integrante della demo end-to-end alla fine del keynote dei Dev Days di OpenAI (sottolineatura nostra):
“…puoi descrivere le funzioni e fare in modo che il modello scelga in modo intelligente di produrre…argomenti per chiamare una o più funzioni. L’API Chat Completions non chiama la funzione ; invece, il modello genera [dati strutturati] che puoi utilizzare per chiamare la funzione nel codice.”
Detto questo, OpenAI rileva anche che questa funzionalità è integrata nel modello e non deve essere spiegata tramite esempi di pochi scatti, come con una libreria come LangChain. Ammettono che le definizioni delle funzioni dell’utente contano rispetto al limite di contesto del modello, quindi c’è ancora spazio per miglioramenti nel ridurre l’overhead richiesto.
Scalabilità u’alta parola che ascolto 1000 volte al mese.
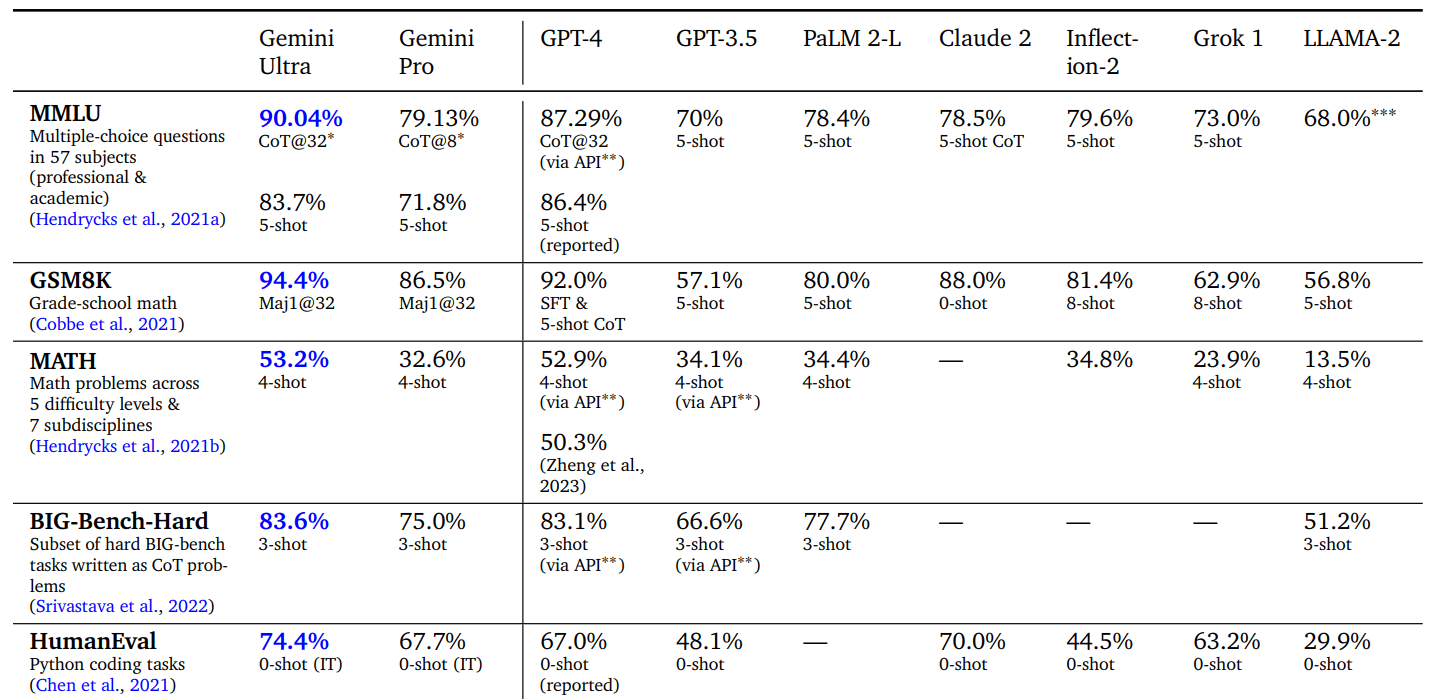
Sta rapidamente diventando sempre più difficile portare avanti lo stato dell’arte destinando maggiori risorse al problema. GPT-4 e Gemini Ultra hanno entrambi un presunto numero di parametri superiore a 1,5 trilioni, ovvero da cinque a dieci volte il numero di parametri degli LLM della generazione precedente.
Questa cadenza di parametri non può continuare senza una sorta di sacrificio in termini di velocità (già un problema quando si tratta di allenamento) o di precisione. Anche le risorse fisiche di calcolo e le materie prime necessarie per alimentarle stanno risentendo della pressione derivante dal ridimensionamento del blitz, come meglio illustrato dalla rinnovata spinta di Microsoft per l’espansione dell’energia nucleare.
Forse, quindi, in futuro gli ingegneri non si chiederanno che tipo di architettura ML, ma piuttosto si chiederanno quanto è grande un LLM di cui ha bisogno la loro applicazione. Questa consapevolezza potrebbe essere stata lo stimolo per Google a rilasciare versioni di Gemini e Microsoft di diverse dimensioni per lanciare Phi-2, fornendo più opzioni a utenti e sviluppatori senza aver bisogno (o assumersi) di risorse di livello hyperscaler per iniziare.
Vale a dire: abbiamo utilizzato Google AI Studio per chiedere a Gemini Pro di eseguire per noi un’attività di contabilità finanziaria personale, estraendo dati da CSV e fogli di calcolo Excel formattati come tabelle delimitate da tabulazioni e convertendoli in un formato contabile a partita doppia – e con un minimo ( contesto “zero-shot”), ha funzionato in modo abbastanza egregio, anche se ha ancora problemi con nomi di colonne diversi ma simili e istruzioni più complesse come “somma i valori dei simboli duplicati”. Sarà un’esperienza interessante vedere se contesti più lunghi su modelli più piccoli consentiranno ai prompt di sistemi complessi di funzionare su un modello di circa 3 miliardi di parametri e di produrre allucinazioni minime o nulle.
Dovro’ pagarmi un’avvocato?
Con il dominio pubblico che lentamente ma inesorabilmente si avvicina ai tesori dei “rich media” del 20° secolo (cioè non solo testo e immagini statiche), concedere in licenza librerie di contenuti per addestrare l’intelligenza artificiale può essere un destino preferibile per nomi come Steamboat Willie .
La causa del New York Times (NYT) contro Microsoft e OpenAI sottolinea con enfasi questo punto. Mentre questa causa si svolge, abbiamo l’opportunità di osservare le regole e i limiti stabiliti per ciò che costituisce l’uso legale dei dati protetti da copyright nei corpora di formazione LLM e la distinzione tra “apprendimento” e “copia” quando si tratta della risposta di un LLM agli input riguardanti tale materiale protetto da copyright. Proprio come Internet negli anni ’90, probabilmente vedremo le risposte legali e la tecnologia stessa modellarsi a vicenda man mano che ci imbatteremo in un’area grigia dopo l’altra.
Mentre l’intelligenza artificiale si fa strada sotto i riflettori, c’è comprensibilmente molta eccitazione, confusione e paura nell’aria. Non abbiamo dubbi che l’intelligenza artificiale sia qui per restare, ma la forma che assumerà e, soprattutto, come si tradurrà in opportunità di business concrete è ancora incerta.
Ciò che non è fluido è sia la pura domanda computazionale dei moderni LLM sia la necessità di un ecosistema snello e con poche barriere per gli sviluppatori e gli utenti finali per attingere a questi modelli in modo economicamente vantaggioso.
È qui che vediamo più sostanza rispetto alla corsa agli armamenti hyperscaler per modelli più grandi e migliori o alla corsa al successo delle startup per la migliore tecnologia applicata .
Inoltre, stiamo cogliendo questa opportunità per orientare la nostra area di interesse per includere l’intelligenza artificiale generativa come tema principale, sia negli aspetti fondamentali che in quelli applicati.
Vediamo ad esempio l’intelligenza artificiale come un punto di svolta per il professionisti per qualsiasi cosa, dall’analisi dei dati all’esecuzione di analisi alla gestione, l’intelligenza artificiale può sbloccare enormi aumenti di produttività su attività che altrimenti potrebbero richiedere ore o giorni per essere completate dai lavoratori entry-level.
Abbiamo anche visto come l’intelligenza artificiale ha livellato il campo di gioco per i non madrelingua inglesi che lottano per comunicare e farsi strada in un mondo incentrato sull’inglese.
Ci auguriamo che troviate interessante la nostra visione del panorama e saremmo interessati anche a sapere quali aspetti, secondo voi, offriranno le maggiori opportunità in futuro.
Lascia un commento
Devi essere connesso per inviare un commento.