
I modelli AI, o modelli di intelligenza artificiale, sono sistemi che utilizzano algoritmi per imitare le capacità dell’intelligenza umana. Questi modelli possono risolvere problemi o svolgere compiti e attività tipici della mente e dell’abilità umane.
Un modello di base è una particolare tipologia di modello di machine learning (ML) che viene addestrato per eseguire una specifica gamma di attività. Questi modelli di base sono stati programmati per avere una comprensione contestuale generica di andamenti, strutture e rappresentazioni. Questa conoscenza di base può essere ulteriormente affinata per eseguire attività specifiche per un dominio in qualsiasi settore.
Per esempio, ChatGPT è un’applicazione chatbot costruita sul modello base GPT-4 di OpenAI.
Le caratteristiche che definiscono i modelli di base e che ne consentono il funzionamento sono due: la capacità di trasferire le informazioni apprese e la scalabilità. La capacità di trasferire le informazioni apprese indica l’abilità di un modello di applicare le conoscenze in una situazione a un’altra. La scalabilità invece si riferisce a dei componenti hardware, le unità di elaborazione grafica (GPU), che consentono al modello di eseguire più operazioni allo stesso tempo.
Molti modelli di base, specialmente quelli impiegati nell’elaborazione del linguaggio naturale (NLP), nella visione artificiale e nell’elaborazione audio, vengono addestrati utilizzando il deep learning. Il deep learning è anche noto come apprendimento neurale profondo o reti neurali profonde e insegna ai computer a imparare tramite l’osservazione, simulando le modalità di acquisizione delle conoscenze tipiche degli esseri umani.
Per quanto non tutti i modelli di base utilizzino trasformatori, queste architetture sono state adottate in maniera diffusa per realizzare modelli di base che prevedevano la presenza di testo.
API OpenAI: L’API di OpenAI offre accesso ai modelli GPT-3 e GPT-4, che possono eseguire una vasta gamma di attività di linguaggio naturale. Inoltre, fornisce accesso a Codex, che è in grado di tradurre il linguaggio naturale in codice.
Gopher: Gopher di DeepMind è un modello linguistico con 280 miliardi di parametri. Ha dimostrato di superare i modelli di linguaggio esistenti per una serie di compiti chiave.
OPT: Open Pretrained Transformers (OPT) di Facebook è una suite di trasformatori preaddestrati solo per decoder. OPT è stato introdotto per la prima volta nei modelli di linguaggio preaddestrati aperti e rilasciato per la prima volta nel repository di metaseq il 3 maggio 2022 da Meta AI.
LLaMA: LLaMA è un modello linguistico fondamentale da 65 miliardi di parametri sviluppato da Meta.
Claude 2: Claude 2 è un assistente AI sviluppato da Anthropic. Ha ricevuto recensioni positive per la sua capacità di ragionamento e inferenza.
Beluga stabile: Beluga stabile è un modello LLamma 65B perfezionato.
Stabile Beluga 2: Stabile Beluga 2 è un modello LLamma2 70B perfezionato.
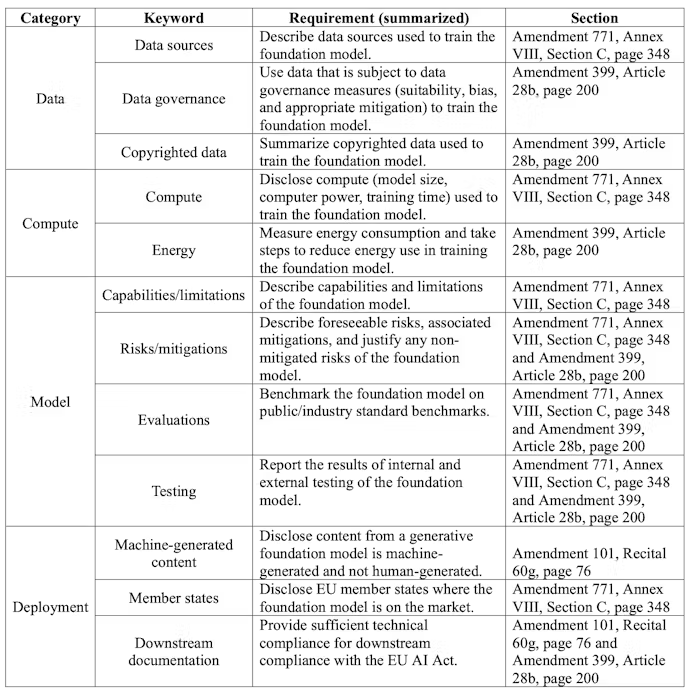
Il Center for Research on Foundation Models (CRFM) di Stanford ha confrontato la bozza dell’AI Act, con i modelli base delle IA più noti come , GPT-4 di OpenAI o Stable Diffusion v2 di Stability AI per verificare quanto l fossero già rispettossi della futura legge.

Non rispettano i requisiti della bozza per descrivere l’uso di dati di addestramento protetti da copyright, l’hardware utilizzato e le emissioni prodotte nel processo di addestramento, e come valutano e testano i modelli.
Perche‘ : La velocità di sviluppo che ha colto tutti impreparati.
Ricorda, queste informazioni sono in giornaliera evulzione Ti consiglio di verificare le informazioni più recenti online o direttamente dalle fonti ufficiali.
Lascia un commento
Devi essere connesso per inviare un commento.