
L’intelligenza artificiale (IA) è in attesa del prossimo grande sviluppo per fare un salto in avanti.
Come ribadito in quella pubblicità degli anni ’80 non serve un pennello grande bensì un Grande Pennello.
La Circuit-Complexity-Theory è una branca della logica computazionale che studia la complessità dei problemi computazionali in termini di circuiti booleani. Recenti progressi in questo campo suggeriscono che potrebbe essere possibile ottenere miglioramenti significativi nelle prestazioni dei modelli di IA attraverso l’uso di tecniche più avanzate di ottimizzazione e approssimazione.
Il GPT-4, rilasciato a marzo possiede circa 1 trilione di parametri, quasi sei volte rispetto al suo predecessore. Secondo le stime fornite dal CEO della società, Sam Altman, il costo di sviluppo si aggira intorno ai 100 milioni di dollari.
Nel contesto di crescita dell’IA, si pone la domanda: “ci serve un Grande pennello ? Questa filosofia ha guidato l’evoluzione dell’IA, enfatizzando la creazione di modelli di machine learning sempre più grandi.
Nonostante l’impero Romano fosse uno degli imperi più grandi e potenti della storia, la sua grandezza alla fine ha contribuito alla sua caduta. La gestione di un territorio così vasto ha portato a problemi logistici, difficoltà di comunicazione, tensioni interne e vulnerabilità ai nemici esterni. Quindi, in questo caso, più grande non significava necessariamente migliore.
Nonostante i successi degli ultimi LLM, ci sono limitazioni da considerare.
L’addestramento di grandi modelli di machine learning richiede molte risorse computazionali, con implicazioni economiche ed ambientali. Inoltre, questi modelli richiedono enormi quantità di dati, sollevando questioni logistiche ed etiche.
Non sempre un modello più grande garantisce un miglioramento proporzionale delle prestazioni, soprattutto se la qualità dei dati non migliora allo stesso ritmo. Questo può portare a problemi di generalizzazione.
La complessità crescente dei modelli rende difficile la loro comprensione e l’individuazione di pregiudizi incorporati, ostacolando la responsabilità e la fiducia nell’IA.
Infine, i costi e le esigenze di risorse dei modelli più grandi possono renderli inaccessibili per entità più piccole, creando una disparità nell’accesso ai benefici dell’IA.
C’è una crescente consapevolezza che l’approccio “più grande è meglio” sta raggiungendo i suoi limiti. Per migliorare i modelli di IA, sarà necessario ottenere più performance con meno risorse.
Un esempio : LLAMA2, allenato con la metà dei Token e rilasciato nel Luglio ‘23, performa peggio di DB-RX, ma non così peggio di quanto si potrebbe pensare, lo si vede bene nelle tabelle di benchmark pubblicate da DataBricks.
DB-RX ha incluso l’addestramento su 2 trilioni di token, l’uso di 3000 GPU H100 e 3 mesi di calcolo e un investimento significativo, stimato tra i 15 e i 30 milioni di euro.
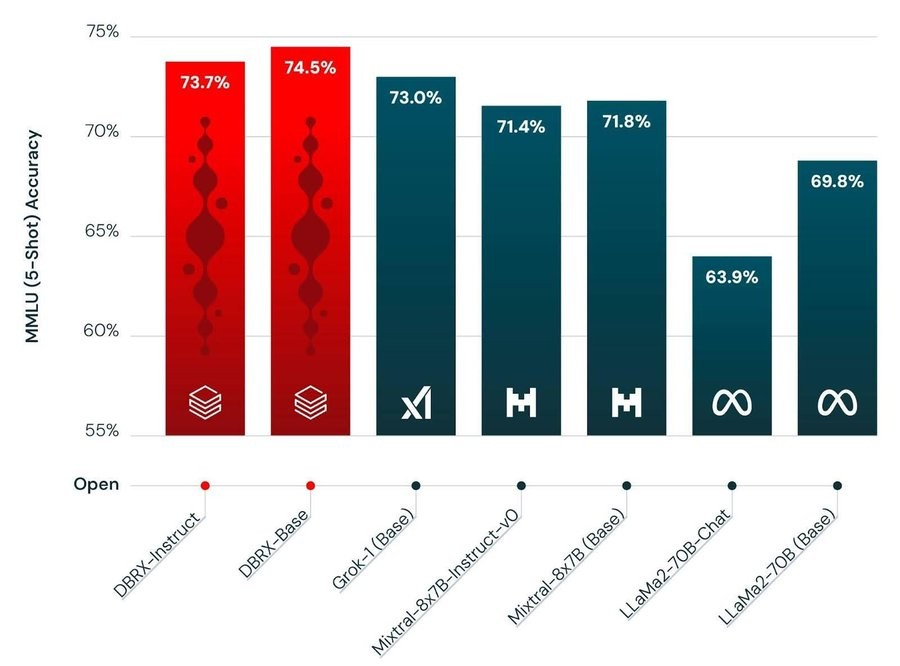
Il concetto : Più performance con meno risorse.
Alternative includono il fine-tuning per compiti specifici, l’uso di tecniche di approssimazione matematica per ridurre i requisiti hardware, e l’adattamento di modelli generalisti in modelli più piccoli e specializzati.
L’importanza del codice di programmazione e dell’hardware su cui viene eseguito è anche in discussione, evidenziando opportunità di miglioramento in questi settori.
Mentre le reti di Head-Attention e le feed-forward networks hanno avuto un ruolo fondamentale nello sviluppo dell’IA, è probabile che avremo bisogno di nuove tecniche e approcci per continuare a fare progressi in questo campo.
Le reti di Head-Attention, come quelle utilizzate nei Transformer, sono state fondamentali per il successo di molte applicazioni di apprendimento automatico. Tuttavia, queste reti possono avere dei limiti, in particolare quando si tratta di gestire sequenze molto lunghe a causa della loro complessità computazionale quadratica.
Le feed-forward networks, d’altra parte, sono state la spina dorsale dell’apprendimento profondo per molti anni. Queste reti sono in grado di apprendere rappresentazioni complesse dei dati attraverso molteplici strati di neuroni artificiali. Tuttavia, anche queste reti possono avere dei limiti, in particolare quando si tratta di modellare le dipendenze temporali nei dati.
Recenti progressi in questo campo suggeriscono che potrebbe essere possibile ottenere miglioramenti significativi nelle prestazioni dei modelli di IA attraverso l’uso di tecniche più avanzate di ottimizzazione e approssimazione.
Come l’adattamento di modelli generalisti in modelli più piccoli e specializzati, e l’esplorazione di nuovi paradigmi di apprendimento automatico.
Mentre restiamo attesa dei prossimi LLama3 e GPTNext, attesi per Luglio Agosto, Fauno (LLM) , sviluppato dal gruppo di ricerca RSTLess della Sapienza Università di Roma addestrato su ampi dataset sintetici italiani, che coprono una vasta gamma di campi come dati medici, contenuti tecnici da Stack Overflow, discussioni su Quora e dati Alpaca tradotti in italiano dovra’ confrontarsi con i numeri e i dati rilasciati da Databricks con gli investimenti di DB-REX e con un ROI che si dimezza ogni 6 mesi e senza sapere cosa uscirà da Meta o OpenAI, i quali giocano un campionato tutto loro dove le GPU si contano a centinaia di migliaia.
Il campo dell’IA è in continua evoluzione e presenta sia sfide che opportunità.
In un mondo in cui le aziende investono miliardi nello sviluppo di Large Language Models (LLM), sorgono preoccupazioni riguardo alla tecnologia della scatola nera che utilizzano. Le query di ricerca LLM richiedono una potenza di elaborazione fino a dieci volte maggiore rispetto alle ricerche standard e possono comportare spese operative milionarie su larga scala. Alcuni LLM proprietari offrono un utilizzo gratuito, ma come recita il vecchio proverbio: “Se non paghi per il prodotto, il prodotto sei tu.” Questo ha spinto alcuni a esplorare approcci alternativi
Le organizzazioni e gli individui che lavorano in questo campo devono essere pronti a navigare in questo panorama in rapida evoluzione..
Lascia un commento
Devi essere connesso per inviare un commento.