Google DeepMind ha recentemente presentato Mixture-of-Depths (MoD), un metodo che aumenta la velocità di elaborazione fino al 50% in compiti come l’elaborazione del linguaggio naturale e la previsione di sequenze complesse.
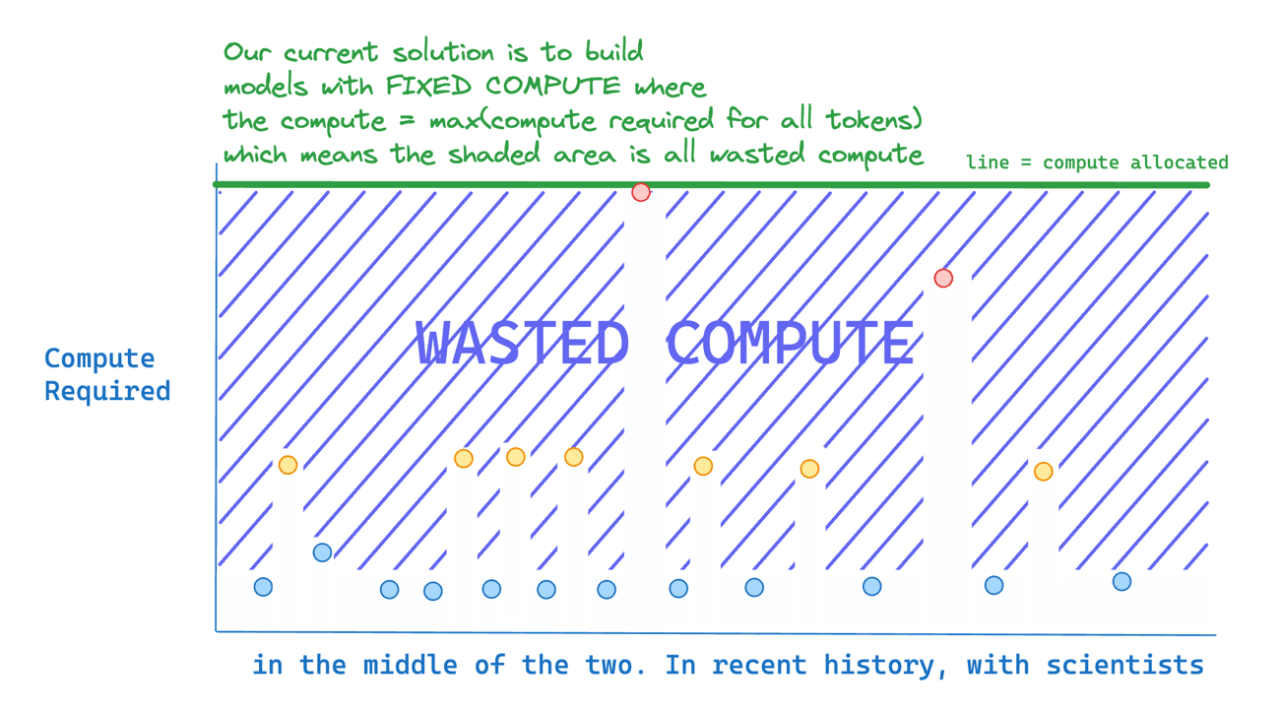
La maggior parte della potenza di calcolo viene sprecata perché non tutti i token sono ugualmente difficili da prevedere. Questo nuovo metodo assegna dinamicamente il calcolo nei modelli transformer, ottimizzando l’uso delle risorse pur garantendo l’accuratezza. Elabora selettivamente i token complessi e salta quelli più semplici, riducendo significativamente il sovraccarico computazionale.
All’interno dei computer, i testi come quelli prodotti da ChatGPT sono rappresentati in forma numerica, e ogni operazione eseguita su di essi è un’enorme sequenza di semplici operazioni matematiche.
Dato che i numeri decimali sono rappresentati in formato “floating point” (“a virgola mobile”), è naturale contare quante operazioni elementari (per esempio addizioni) su tali numeri possono essere eseguite in un certo tempo: floating point operations, ovvero FLOPs
I transformers sono modelli di apprendimento automatico basati sull’attenzione (attention-based) per elaborare sequenze di input, come le sequenze di parole in un testo. L’attenzione permette al modello di dare maggiore peso a determinate parti dell’input, in modo da prestare maggiore attenzione a informazioni rilevanti e ignorare informazioni meno importanti.
Questa capacità di prestare attenzione a parti specifiche dell’input rende i transformers particolarmente adatti all’elaborazione del linguaggio naturale, dove l’informazione rilevante può essere dispersa all’interno di una sequenza di parole.
I modelli di linguaggio basati su transformer distribuiscono uniformemente i FLOP attraverso le sequenze di input.
In questo lavoro, i ricercatori dimostrano che i transformer possono invece imparare a assegnare dinamicamente i FLOP (o calcoli) a posizioni specifiche in una sequenza, ottimizzando l’allocazione lungo la sequenza per diversi strati attraverso la profondità del modello. Il nostro metodo impone un budget totale di calcolo limitando il numero di token (k) che possono partecipare ai calcoli di self-attention e MLP in un dato strato.
I token da elaborare sono determinati dalla rete utilizzando un meccanismo di instradamento top-k. Poiché k è definito a priori, questa semplice procedura utilizza un grafo di calcolo statico con dimensioni di tensori note, a differenza di altre tecniche di calcolo condizionale. Tuttavia, poiché le identità dei token k sono fluide, questo metodo può sprecare i FLOP in modo non uniforme attraverso le dimensioni del tempo e della profondità del modello.
Quindi, la spesa di calcolo è completamente prevedibile nel totale complessivo, ma dinamica e sensibile al contesto a livello di token. Non solo i modelli addestrati in questo modo imparano a assegnare dinamicamente il calcolo, ma lo fanno in modo efficiente. Questi modelli corrispondono alle prestazioni di base per FLOP equivalenti e tempi di addestramento, ma richiedono una frazione dei FLOP per passaggio in avanti e possono essere più veloci del 50% durante il campionamento post-addestramento.
Questo documento è un altro promemoria che i Modelli di Linguaggio a Lungo Termine (LLM) sono ancora nelle loro prime fasi: lenti, ampi e inefficienti. Creare modelli economici e veloci aprirà un mondo di possibilità, come la capacità di eseguire modelli localmente sui nostri telefoni e GPU. Potrebbe anche ridurre drasticamente i costi di addestramento e esecuzione degli LLM.
Newsletter AI – non perderti le ultime novità sul mondo dell’Intelligenza Artificiale, i consigli sui tool da provare, i prompt e i corsi di formazione. Iscriviti alla newsletter settimanale e accedi a un mondo di contenuti esclusivi direttamente nella tua casella di posta!
Lascia un commento
Devi essere connesso per inviare un commento.