
Uno dei limiti evidenti emerso dall’uso dei chatbot di nuova generazione, disponibili al pubblico da fine 2022, è la dispersione nella qualità ed accuratezza delle risposte evidenziata da questi strumenti. Come abbiamo già avuto modo di vedere all’interno di questo portale, il limite oggettivo degli LLM è che essi sono dipendenti dalla qualità delle informazioni con cui sono stati alimentati ed allenati, informazioni che sono state ricavate da materiale reperibile in rete, e filtrato da operatori umani incaricati di censurare i contenuti ritenuti non idonei.
Mentre questo approccio è stato vincente per creare un’applicazione in grado di dialogare con gli utenti utilizzando un linguaggio naturale – e il grado di interesse da parte di tutta la società nel suo complesso è segno tangibile del successo sin qui raccolto dai vari prodotti di AI “di intrattenimento” – gli svantaggi di questo approccio non hanno tardato a manifestarsi a coloro che intendevano fare affidamento sui LLM in ambiti strettamente legati alla conoscenza e alla produzione di contenuti ed applicazioni “competenti”.
Pochi giorni dopo il rilascio al pubblico, il portale Stackoverflow procedeva infatti alla messa al bando di risposte generate tramite AI, in quanto utenti esperti avevano subito notato la presenza di quegli errori grossolani che oggi conosciamo con il termine di “allucinazioni”, un problema tipico degli LLM
che non distingue tra concetti di plausibilità linguistica e accuratezza fattuale.
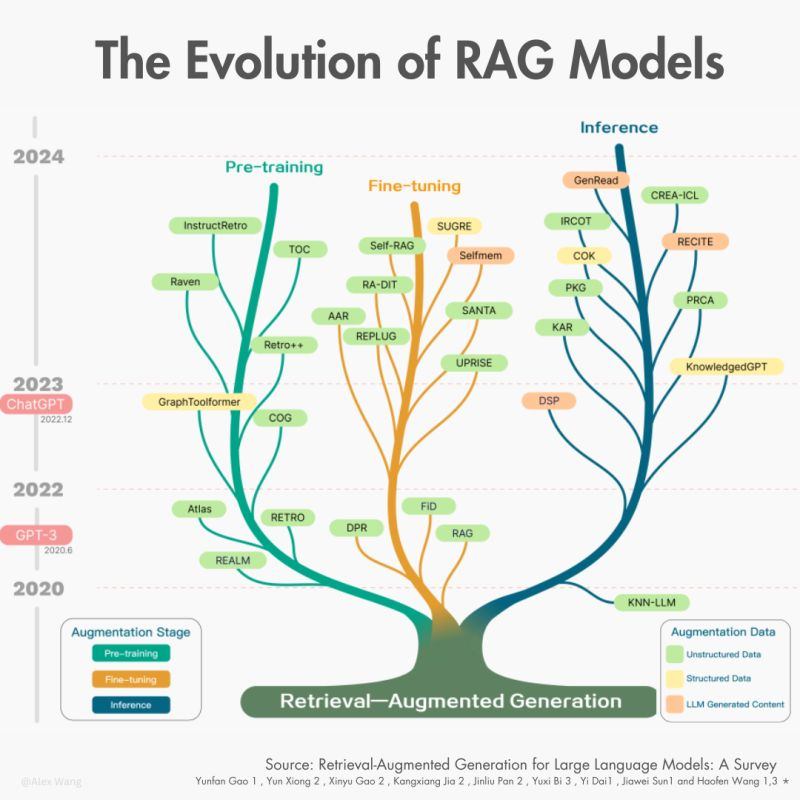
Dalla necessità di poter disporre di uno strumento “diversamente intelligente”, che possa dialogare con gli utenti sulla base di competenze e conoscenze reali si è velocemente affermato l’approccio RAG, acronimo di Retrieval Augmented Generation. Questo acronimo indica la tecnica per la generazione di testi “aumentati” dal recupero di dati puntuali e specifici di varia natura, spesso di natura proprietaria: manuali, competenze professionali o aziendali, scritti accademici, dati provenienti da interrogazioni di database strutturati o non strutturati; oppure leggi o direttive.
Un LLM usa questi dati in modo prioritario per produrre il testo di senso compiuto ed in linguaggio “naturale” (ossia il linguaggio con il quale stiamo leggendo queste righe), ovviando alla problematica legata alle allucinazioni causate dal materiale eterogeneo con il quale è stato allenato.
Grazie a queste premesse tecniche è ora possibile ipotizzare di poter arricchire molti processi che coinvolgono portatori d’interessi interni ed esterni.
Cube Finance – azienda elvetica storicamente attiva nelle soluzioni software nel settore finanziario – da noi interpellata nell’ambito di una scambio di vedute sullo stato del mercato delle nuove tecnologie AI ci conferma come la tecnologia attraverso l’intelligenza artificiale abbia la possibilità di esplodere in modo dirompente e di riqualificare o migliorare flussi di lavoro che da anni domandano ottimizzazioni, maggiore precisione, flessibilità, velocità, nel rispetto contestuale delle necessità dell’interlocutore.
La software house svizzera ha utilizzato proprio queste tecnologie per sviluppare un chatbot ad uso professionale (CubeBot Pro), “wrapper” dei migliori LLM presenti sul mercato per offrire al mondo dei professionisti e delle imprese una piattaforma “no code” per adottare gli LLM nelle proprie attività.
“Sviluppare internamente la piattaforma CubeBot Pro non solo ci ha dato grande consapevolezza dei nostri mezzi sul tema AI ma, soprattutto, ci permetterà di offrire i nostri servizi conoscendo i pregi ed i limiti di tutte le tecnologie utilizzate. Rispetto agli integratori di sistemi che offrono l’integrazione di chatGpt con i sistemi aziendali, siamo in grado di sapere esattamente dove sono salvati i dati, perché le risposte sono a volte incoerenti, perché i tempi di risposta sono diversi… insomma rispetto agli altri abbiamo maggior controllo” afferma Stefano Zanchetta, CEO di Cube Finance.
Innumerevoli sono i casi citati dall’azienda con sede a Mendrisio: la stesura della documentazione legale da parte degli operatori che intendono offrire servizi in criptovalute; la fornitura di pareri legali in ambito civilistico, costruite a partire da documenti rappresentanti casistiche pluridecennali; sportelli cliente evoluti nell’ambito della sanità privata, in alcuni casi “aumentati” da esperienze immersive; assistenza nella valutazione di effetti farmacologici; manuali di assistenza (ad esempio nell’industria aerospaziale) supportati da strumenti di visualizzazione immersiva e via discorrendo.
Tuttavia l’onda dell’entusiasmo – o dell’hype a seconda della prospettiva – va parzialmente moderata quando si considerano i tanti passi necessari per garantire la sicurezza dei dati sensibili, siano essi proprietà intellettuale o legati alla sfera delle persone fisiche o giuridiche. Con ciò si evince che le competenze pregresse maturate di qualunque azienda che fornisca il servizio di chatbot debbano essere vagliate con cautela, assicurandosi che vi siano le dovute certificazioni (es. ISO 27001) e la verifica della capacità dell’integratore a saper trattare i dati sensibili sotto il profilo della sicurezza e della riservatezza, aspetti che non devono passare in secondo piano, nemmeno in questo momento di euforia e di aggressiva profilazione popolare “pro AI”. L’ottemperanza a normative nazionali e internazionali (GDPR) diventano un punto essenziale nel garantire il necessario rispetto di tutte le regole.
Chiedendo poi di nuovo a Stefano Zanchetta quali aspettative lui abbia in tema di chatbot, la risposta è che “i chatbot attualmente rappresentano il mezzo più immediato per il mondo dei professionisti e delle imprese di gestire l’adozione dell’AI, mitigando il rischio di non aderire a questa rivoluzione. Riteniamo che i prossimi anni vedranno un’adozione con crescita esponenziale di questi strumenti e che gli stessi cambieranno in forma e sostanza, passando dal testo scritto alla parola, magari integrata in alcuni dalla realtà immersiva e arrivando a livelli di efficienza sempre più sorprendenti. Sarà anche opportuno adottare dei sistemi “al di sopra” degli LLM per poter scegliere tra un modello o l’altro, in modo trasparente, senza dover rivedere la propria architettura di sistema.”
Lascia un commento
Devi essere connesso per inviare un commento.